Fighting Fakes Fairly
I just wrapped up the first quarter of my master’s degree program. In my project-driven Machine Learning class, I chose to work on a fake face detection task. I picked this topic mostly because I had no experience with computer vision or convolutional neural networks (CNNs) and wanted to try something totally new to me, plus I knew that there was an obvious ethics component to facial recognition AI and wanted to feature that in my work.
I wasn’t expecting the topic to be quite so timely, but after Google fired Timnit Gebru for questioning both their AI ethics and their diversity, equality and inclusion practices, I saw a jaw-dropping thread pop up in my Twitter feed. Someone had created a fake account, using GAN generated fake face profile images, claiming to be one of Dr. Gebru’s former colleagues, in order to smear her reputation.
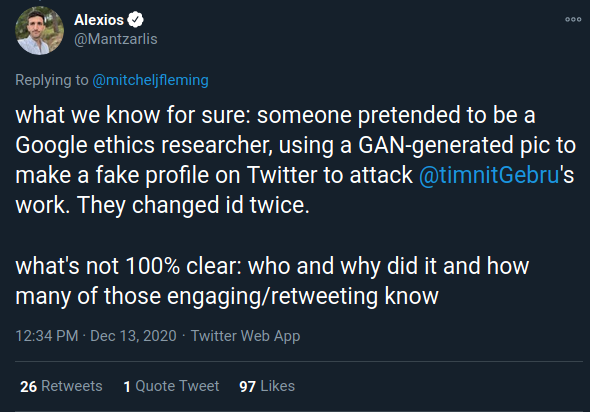
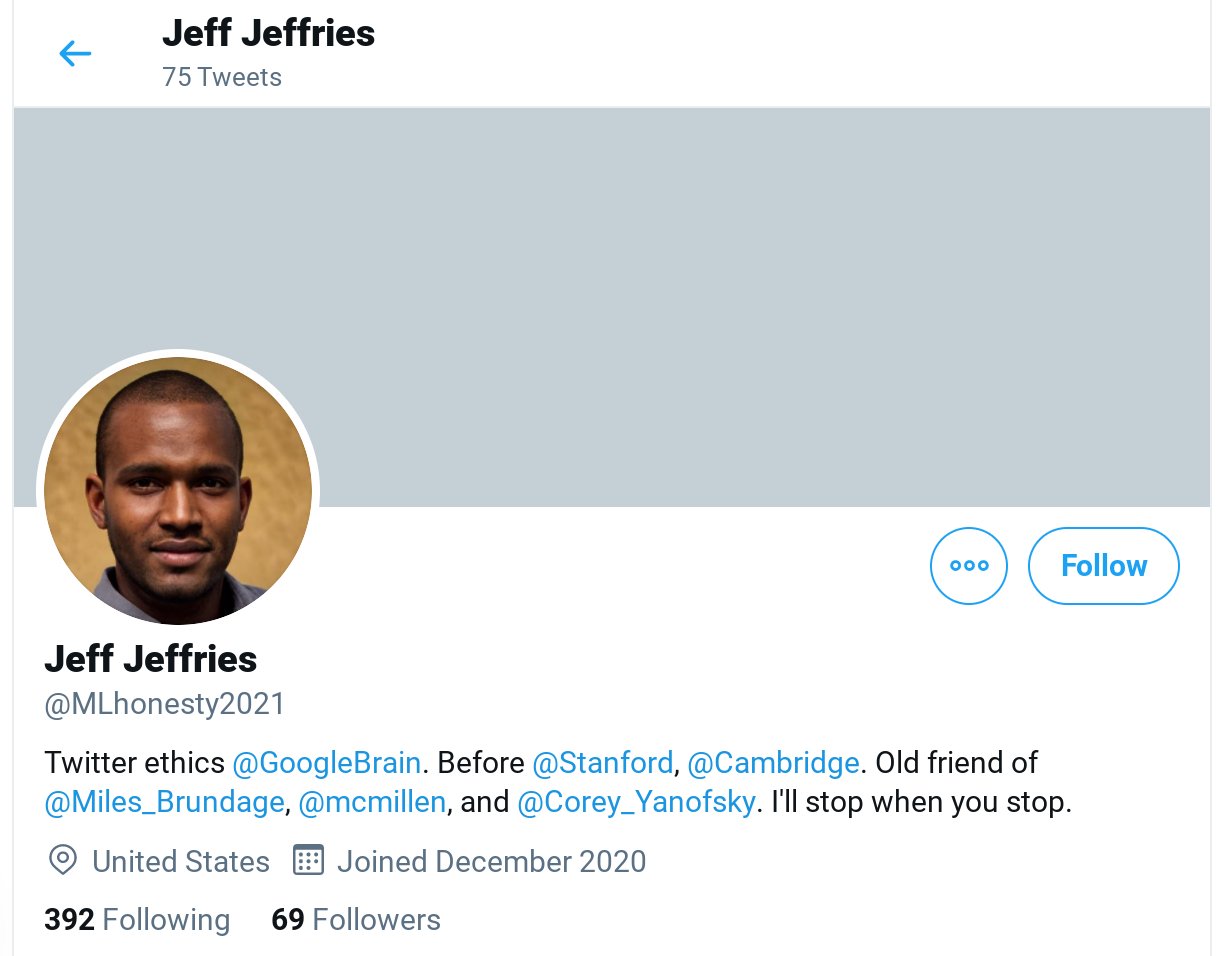
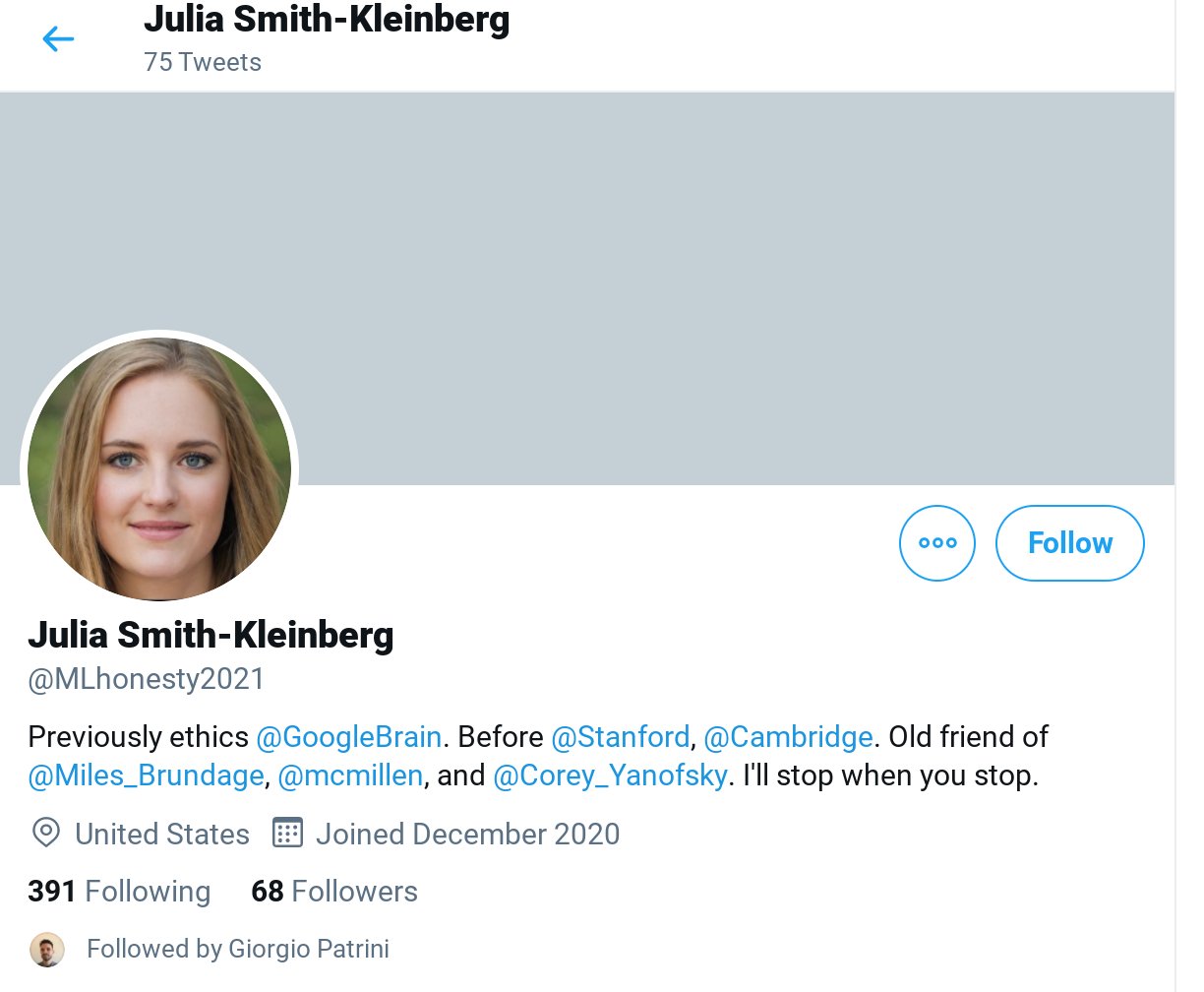
Even worse, a professor emeritus from the UW CSE department, Pedro Domingos, engaged with and even retweeted this account, apparently not realizing it was a fake:
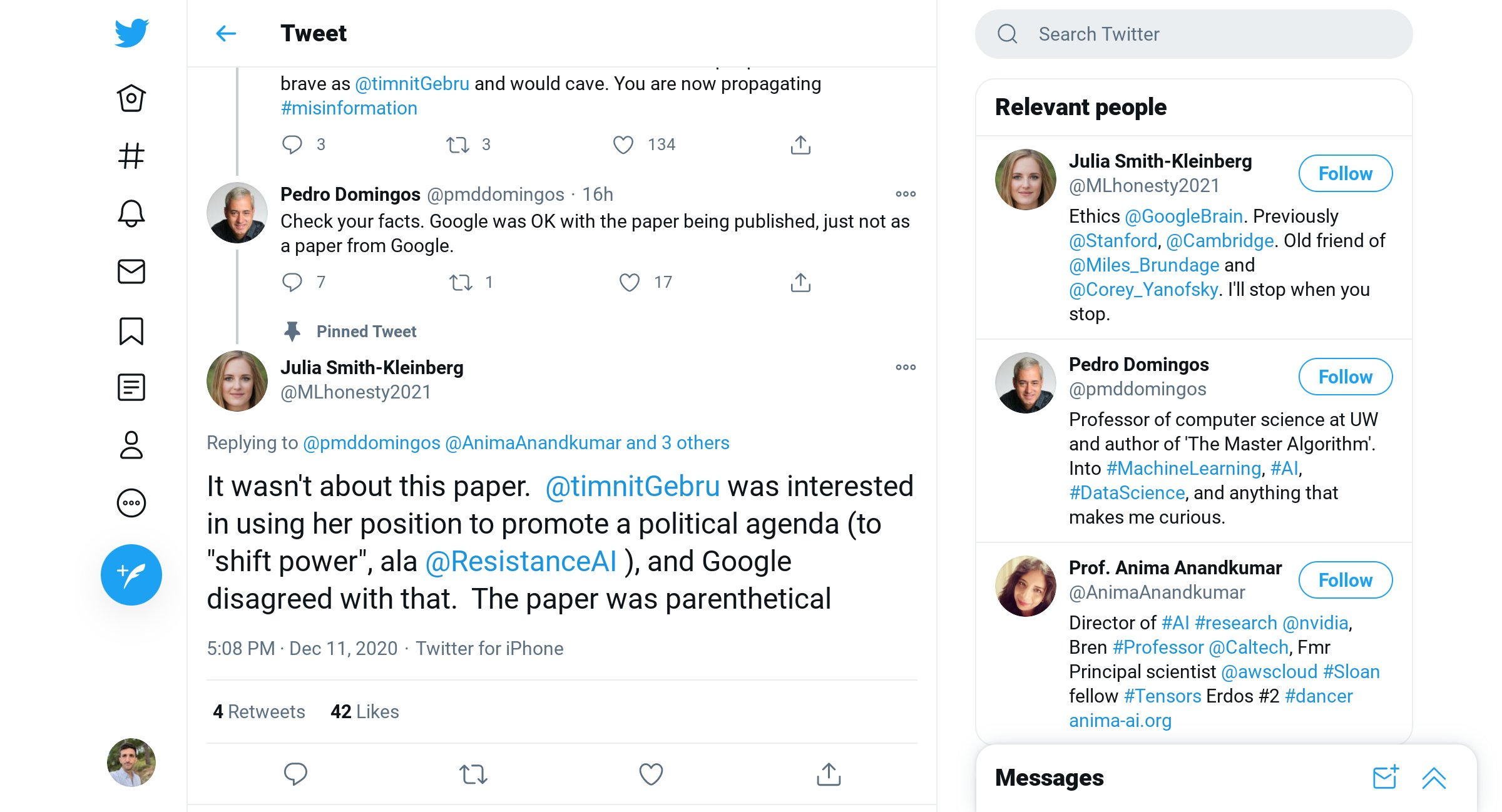
This made it very clear to me that “deep fakes” is not a toy problem or a hypothetical future problem, but that the technology is being deployed right now to spread disinformation online. So this points to the need for technology to detect and flag fakes, in order to keep up in the “arms race.”
My project team took the obvious approach to the problem–get a dataset consisting of real human face images and another dataset of fake ones generated by StyleGAN, and then train a CNN model to distinguish between the two datasets. We used Keras, and while it was a bit frustrating to get it configured and working on top of CUDA, because TensorFlow requires older versions of the NVIDIA libraries, we were able to get it working. I hacked together a little Python framework to run model training with a specified set of model hyperparameters and image preprocessing steps, saving the model weights and accuracy results to files to track our progress. We ended up going with a 10-layer network based on the VGG-16 architecture but simplified to avoid overfitting, because the problem is much less complex than ImageNet.
While we got promising results (>97% test accuracy) on the original datasets, we knew that face image datasets tend to have selection bias toward middle-aged, white faces, so we wanted to test whether our model performed equally well on subjects of different demographics.
In order to conduct that fairness assessment, we needed a demographically labeled dataset of both real and fake faces, so we took the FairFace dataset, then used pixel2style2pixel as an autoencoder, to embed each image into the latent space of the StyleGAN network and then extract it back out into an image.
The results of this process were pretty interesting. The pixel2style2pixel model was able to reconstruct faces very similar to the originals, removing things like hands partially covering faces and bruises and blemishes, though it sometimes made mistakes like misinterpreting head coverings as hair. Here are some samples:

Here’s my own face before and after running through the face falsifier network, which feels pretty eerie to look at:

What we found in the process, though, was that our model trained on the first dataset totally failed to generalize to the second dataset, with accuracy only in the mid 50s, only marginally better than a coin toss. So we decided not to bother with a fairness assessment on a clearly useless model. Instead, we retrained and scored the model on a combined dataset drawn from both datasets. We found that this new model performed better than our first model on both the original dataset and the combined dataset, probably due to the additional training examples, and it also performed with almost exactly the same metrics across demographic splits of male/female, white/non-white, black/non-black, elderly/non-elderly, and child/non-child.
There’s a ton more work to be done in the space, and I still have doubts about whether the model really detected something intrinsic to fake faces that will generalize well across more datasets. But for now, I think this experience demonstrates the value of using a diverse, heterogenous input dataset, testing the model on truly out-of-sample data, and considering and planning for a model fairness assessment up front.
Our code is available on GitHub: https://github.com/alexkyllo/fake-faces/
Winter quarter will be a little change of pace as I’m taking High Performance Computing, which will focus on GPU programming with CUDA. I’m pretty excited for it because I hope to brush up on my computational linear algebra and better understand what is actually happening when I train a neural network model on my GPU.